
Last October, I attended a conference called REDeploy 2019 dedicated to resilience engineering. Old news, you say? Just in time, says I! Today, when almost all conferences and fora have moved online, we appreciate offline meetings more, and value networking like never before. Here, I want to share with you the lessons I learned from one of the most informative events of the last year, introduce you to experienced experts in the field, and share a few thoughts on the most critical quality we all need these days: the ability to deal with failures and move forward regardless of pressure.
Though the term has been in use for a decade already, resilience engineering still needs a bit of explanation. First, it is important to understand that resilience engineering is a cross-disciplinary field. It pursues research, formalization, and formation of practices that increase the ability of complex socio-technical systems to resist unusual situations, to adapt to accidents, and keep improving adaptability.
For many years, software development has been seen through a mechanistic lens. We believed that we could develop failure-free software. Even if an accident happens, we thought, there will be an identifiable root cause, which we can solve and thereby prevent the recurrence of similar mistakes in the future. We were sure that the number of errors was bounded, so in the end it would be possible to correct all the errors that can cause accidents. For more on that, check out this great article by J. Paul Reed: Dev, Ops, and Determinism.
The same technical approach was applied to how people interact during an accident. Many believed that it was enough to create some toolkit, give it to people, and voila—they solve every problem and don’t make any mistakes.
In fact, the problem is that software is constantly being updated. It becomes complicated, siloed, and branched. Every accident has its own separate root cause, which might even be outside the system. Finally, people can make mistakes when they communicate with each other about the ways to solve the accident.
Thus, the task is no longer about avoiding errors and accidents in the system. The task is to train people and systems to guarantee that future accidents make the least impact on the system, its users and creators.
Software development has long been aloof from the other, “offline” engineering disciplines that have long been using harm reduction practices. To prevent accidents, those practices refer more to people rather than tools and technical solutions.
Resilience engineering focuses on the following questions:
- What cultural and social peculiarities of human interaction should be well understood to better predict what can and cannot occur in communication between people during an accident? How can this process of adaptation and communication be improved? And, on the flipside, when and how can the process go wrong?
- What knowledge from other disciplines can we apply to make the system more flexible and resilient in the event of an accident?
- How shall we organize training and human interaction to ensure that, in the event of an accident, we can minimize the damage and the stress from resolving it?
- What technical solutions or practices will help here?
- How can deliberate actions enhance the system's stability and adaptability to accidents?
Those were the key issues of the October REDeploy2019 conference. Let's look at some presentations.
- A Few Observations on the Marvelous Resilience of Bone and Resilience Engineering. Richard Cook
This speaker deserves a separate introduction. Richard Cook is a research scientist, physician, and one of the main communicators of resilience engineering in the IT sphere. Together with David Woods and John Alspaugh (the man who actually launched DevOps as a separate field by making Dev and Ops work together), Cook founded Adaptive Capacity Labs, which introduces sustainable engineering principles in other organizations' matrices.
It is important to note that REDeploy is not purely an IT conference, and this presentation proved that. A large part of the presentation was a detailed analysis of how a broken bone gets healed. That healing process was presented as an archetype of resilience. Without external medical help, bones coalesce incorrectly. Medicine has been learning to heal bones by studying the healing process. In fact, medicine does not heal bones, it enacts processes that promote healing.
In general, the treatment process can be divided into two categories:
· Treatment as a process that creates the most favorable conditions for bone healing (for example, we apply gypsum to hold the bone steady);
· Treatment as a process to “improve” bone healing (we understand the biochemical processes involved, and apply drugs that speed up those processes).
And here is the thing: that presentation uncovered the key aspects for the whole sector. Why do we need to understand the socio-technical processes at work during an accident?
By understanding how the “treatment” mechanism (e.g., solution of an emergency situation) works, we can, first of all, organize conditions that will minimize damage, and, second of all, speed up the process of incident resolution. We can't make people stop breaking their bones. But we can improve their healing processes.
2. The Art of Embracing Failure at Scale. Adrian Hornsby
This presentation is purely IT and shows the evolution of resilience in the AWS infrastructure. Without getting into technical details (you can check them via the link above), let's see the core thesis of the presentation.
When building various systems, AWS designs the architecture from the following point of view: an accident is going to happen sooner or later.
Thus, the system's architecture should be designed to limit the “blast radius” in case of an accident. Customers' DBs, for example, their data stores, are all divided into groups of “cells,” and traffic from one customer only affects the users of that customer's cell. Cell replicas do not duplicate the original cells. By being shuffled all together, they thereby limit the radius of impact to a minimum.

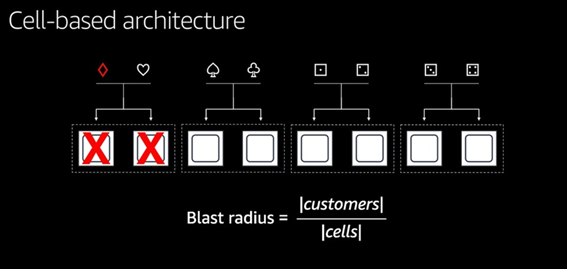
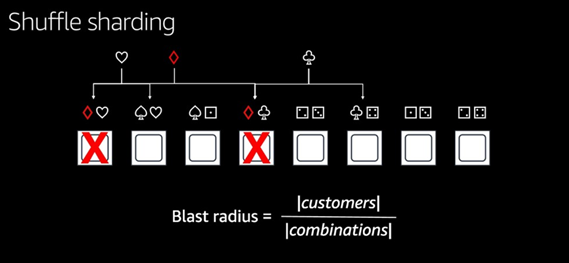
By increasing the number of such combinations, we mitigate the risk of customer engagement in case of an accident.

3. Getting Comfortable with Being Underwater. Ronnie Chen
This was a presentation by a Twitter manager who has experience in technical deep-sea diving. He talked about the specifics of the security measures for diving.
Team deep diving is a process that’s associated with greater risk. When you organize a deep dive, you can't think that deep diving will only be possible when there are no risks. If that were the case, there would be no deep diving at all.
Problems may happen one way or another, and that's fine. Chen associates taking chances responsibly with a tool for human development. If we offset the risks, we will limit our potential. The task here, again, is to organize the easiest way to solve problems if and when they materialize.
How will teams deal with the pressure while performing risky activities? Here are a few rules of diving team engagement:
- There must be a reliable and unbreakable communication between the team members, and maximum psychological security shall be guaranteed for everyone. The latter means, among other things, that everyone has an opportunity to terminate the dive at any moment (no criticism allowed).
- Green light for mistakes. Everyone has a right to make mistakes, which are inevitable in the working process. Accusations of mistakes are unacceptable.
- The team can redefine the project's objectives and its success during diving and according to changing conditions.
- The team is composed of people with similar stress resistance; the least experienced member guides the team’s actions.
- One of the most important tasks is to build experience of each team member. Besides first-hand experience, there is a focus on fail stories. All team members share their stories of failed dives or making mistakes to the whole team, so everyone gains useful experience.
- Postmortem (those fail stories) are not there to find the root cause, which in most cases does not exist, but to share the experience.
4. The Practice of Practice: Teamwork in Complexity. Matt Davis
Considering the fact that in case of an accident, engineers act mostly intuitively, intuition was compared by the presenter to musical improvisation.
Musical improvisation is an intuitive process of playing music, where intuition is based on previous experience, including knowledge of musical scales, previous improvisations, and teamwork.
Plus, there is a bi-directional process: experience builds intuition, while analysis of intuitive actions forms the processes (in music, for example, the musical notes of a created composition are written down; in technologies, the process of fixing the accidents is described).
There are two ways to develop/ train intuition:
- Postmortem. Instead of being a means to assign blame or prevent problems in the future, a postmortem should be a tool to accumulate and share experience. Do regularly share stories of dealing with accidents to pass on your experience of solving different problems!
- Chaos Engineering as a way to build experience under controlled conditions. By artificially creating an accident in the system, we allow the engineers to gain intuitive experience. We can determine the stack of technologies where we want to build capabilities, and, at the same time, limit the blast radius for the system.